This notebook aims to solve the titanic classification problem using pytorch
Imports
Code
# Data aggimport pandas as pdimport numpy as np# Vizfrom matplotlib import pyplot as pltimport seaborn as snsplt.style.use('seaborn')# Torchimport torchimport torch.nn as nnimport torch.nn.functional as Ftorch.backends.cudnn.deterministic =True# metricsfrom sklearn import metrics# Data processingfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
Data
Code
# compared with dataset from kaggle, the one provided by standford has less featuresdf = pd.read_csv('https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv')df.columns = df.columns.str.lower().str.replace('/','_').str.replace(' ','_')# drop. the namedf = df.drop(['name'],axis=1)# encode the values from the sex columndf.sex = df.sex.replace({'male':1,'female': 0})df[:3]
Keep this part into one cell, it willl make the model development and testing easier
Code
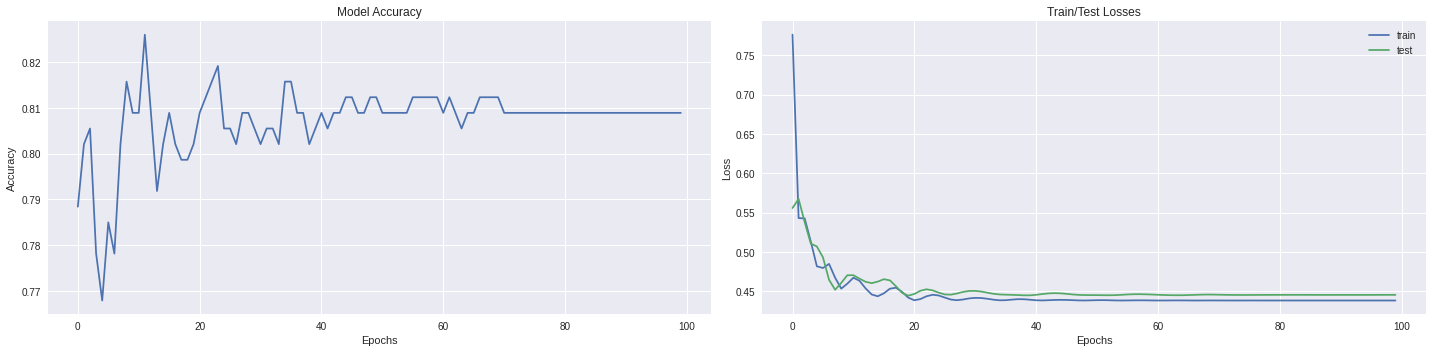
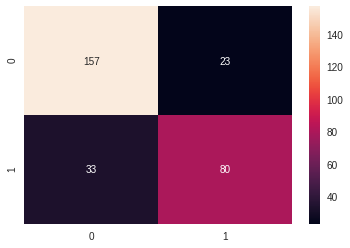
### Here is our neural networkclass Net(nn.Module):def__init__(self):super(Net,self).__init__()# takes an imput of 6 features, and spits out a vector of size 256self.lin1 = nn.Linear(in_features=6,out_features=256,bias=True)# the second layer takes the 256 vector and process it into a vector of size 64self.lin2 = nn.Linear(in_features=256,out_features=64,bias=True)# the last layer takes the 64 size vector and returns the output vector which 2 == number of classesself.lin3 = nn.Linear(in_features=64,out_features=2,bias=True)# here we take the input data and pass it through the chain of layersdef forward(self,input): x =self.lin1(input) x =self.lin2(x) x =self.lin3(x)return x# instance our modelmodel = Net()# set the number of epochsepochs =100# criterion aka loss function -> find more on pytorch doccriterion = nn.CrossEntropyLoss()# optimizeroptimizer = torch.optim.Adam(model.parameters(), lr=0.01)# create 3 lists to store the losses and accuracy at each epochtrain_losses, test_losses, accuracy = [0]*epochs, [0]*epochs,[0]*epochs# in this current case we don't use batches for training and we pass the whole data at each epochfor e inrange(epochs): optimizer.zero_grad()# Comput train loss y_pred = model(x_train) loss = criterion(y_pred, y_train) loss.backward() optimizer.step()# store train loss train_losses[e] = loss.item()# Compute the test statswith torch.no_grad():# Turn on all the nodes model.eval()# Comput test loss ps = model(x_test) loss = criterion(ps, y_test)# store test loss test_losses[e] = loss.item()# Compute accuracy top_p, top_class = ps.topk(1, dim=1) equals = (top_class == y_test.view(*top_class.shape))# store accuracy accuracy[e] = torch.mean(equals.type(torch.FloatTensor))# Print the final informationprint(f'Accuracy : {100*accuracy[-1].item():0.2f}%')print(f'Train loss: {train_losses[-1]}')print(f'Test loss : {test_losses[-1]}')# Plot the resultsfig,ax = plt.subplots(1,2,figsize=(20,5))ax[0].set_ylabel('Accuracy')ax[0].set_xlabel('Epochs')ax[0].set_title('Model Accuracy')ax[0].plot(accuracy)ax[1].set_ylabel('Loss')ax[1].set_xlabel('Epochs')ax[1].set_title('Train/Test Losses')ax[1].plot(train_losses, label='train')ax[1].plot(test_losses, label='test')ax[1].legend() plt.tight_layout()
Accuracy : 80.89%
Train loss: 0.4383288621902466
Test loss : 0.4455047845840454