Autoencoders and Fraud Detection




Imports
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.model_selection import train_test_split
from keras.layers import Input, Dense
from keras.models import Model, Sequential
from keras import regularizers
import xgboost as xgb
plt.style.use('seaborn')
The datasets contains transactions made by credit cards in September 2013 by european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
It contains only numerical input variables which are the result of a PCA transformation. Unfortunately, due to confidentiality issues, we cannot provide the original features and more background information about the data. Features V1, V2, … V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are 'Time' and 'Amount'. Feature 'Time' contains the seconds elapsed between each transaction and the first transaction in the dataset. The feature 'Amount' is the transaction Amount, this feature can be used for example-dependant cost-senstive learning. Feature 'Class' is the response variable and it takes value 1 in case of fraud and 0 otherwise.
df = pd.read_csv('data/creditcard.csv')
df
Feature Correlation
corr = df.corr(method='spearman')
plt.figure(figsize=(12,7))
sns.heatmap(corr[corr > .2],annot=True,fmt='.2f',cmap='Blues');

Select Features for modeling
features = ['Time','V1','V2','V3','V4','V5','V6','V7','V8','V9','V10','V11','V12','V13','V14','V15','V16','V17','V18','V19','V20','V21','V22','V23','V24','V25','V26','V27','V28','Amount']
target = 'Class'
Train Test Split
train, test = train_test_split(df, test_size=0.33,random_state=42,stratify=df[target])
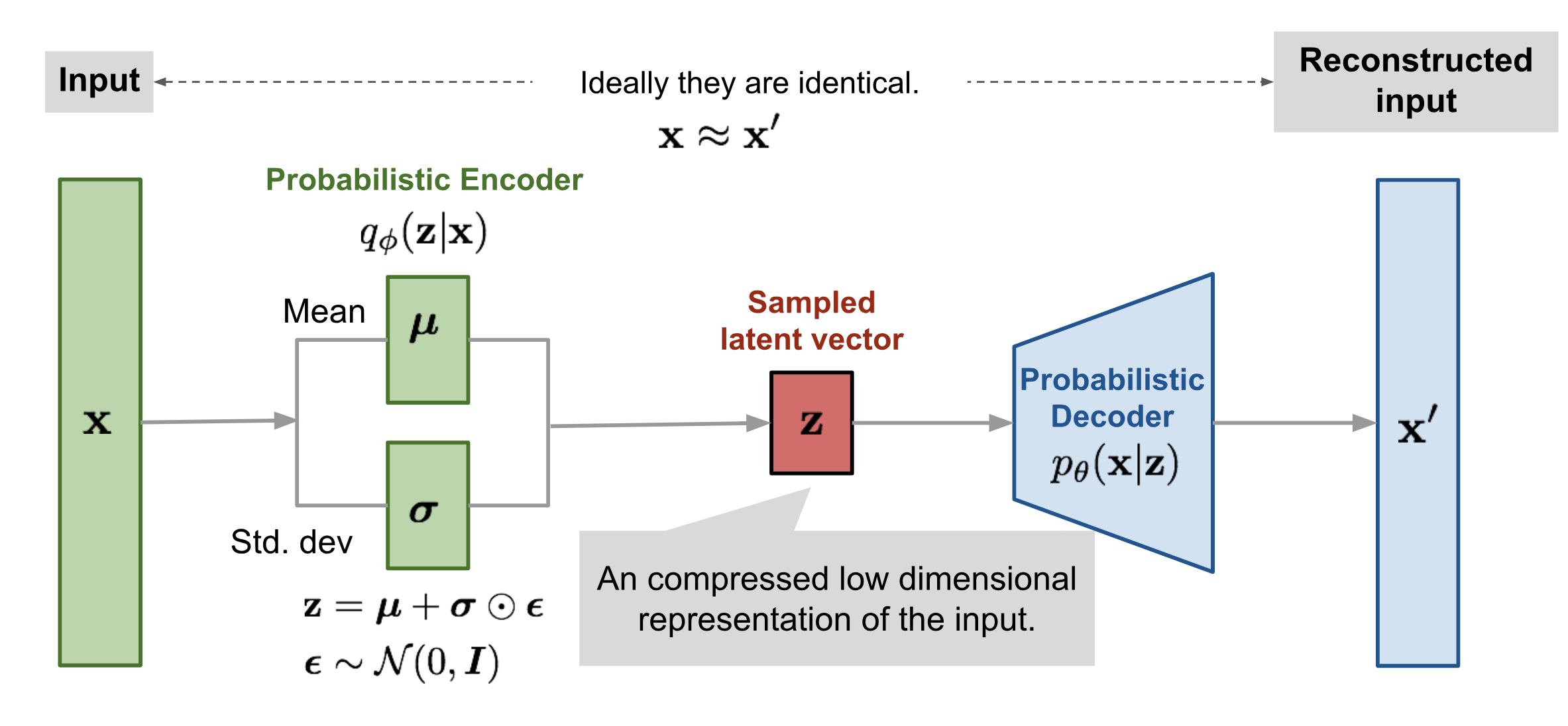
Autoencoder is a neural network designed to learn an identity function in an unsupervised way to reconstruct the original input while compressing the data in the process so as to discover a more efficient and compressed representation.
The encoder network essentially accomplishes the dimensionality reduction, just like how we would use Principal Component Analysis (PCA) or Matrix Factorization (MF) for. In addition, the autoencoder is explicitly optimized for the data reconstruction from the code. A good intermediate representation not only can capture latent variables, but also benefits a full decompression process.
Define a generalistic Auto Encoder
def autoencoder(shape,regularizer=regularizers.l1(10e-5)):
## input layer X_train.shape[1]
input_layer = Input(shape=(shape,))
## encoding part
encoded = Dense(100, activation='tanh', activity_regularizer=regularizer)(input_layer)
encoded = Dense(50, activation='relu')(encoded)
## decoding part
decoded = Dense(50, activation='tanh')(encoded)
decoded = Dense(100, activation='tanh')(decoded)
## output layer
output_layer = Dense(shape, activation='relu')(decoded)
autoencoder = Model(input_layer, output_layer)
autoencoder.compile(optimizer="adadelta", loss="mse")
return autoencoder
Pass the shape of your X_train
encoder = autoencoder(train[features].shape[1])
Keras model Summary
encoder.summary()
Let's normalize our data
scaler = preprocessing.MinMaxScaler().fit(train[features].values)
scaled_data = df.copy()
scaled_data[features] = scaler.transform(df[features])
fraud, non_fraud = scaled_data.loc[scaled_data[target] == 1],scaled_data.loc[scaled_data[target] == 0]
Now we can fit our Autoencoder
encoder.fit(scaled_data[features], scaled_data[features], epochs = 20, shuffle = True, validation_split = 0.25)
We extract the hidden layers so then our model can encode given data
hidden_representation = Sequential()
hidden_representation.add(encoder.layers[0])
hidden_representation.add(encoder.layers[1])
hidden_representation.add(encoder.layers[2])
then we encode the two dataframes that contains fraudulent and non fraudulent samples
fraud_hidden = hidden_representation.predict(fraud[features])
non_fraud_hidden = hidden_representation.predict(non_fraud[features])
finally we ca bring them back together into a dataframe where we can see that we have a higher number of features than the initial one, this being a result of our 3rd layer which has an output shape of 50
encoded_df = pd.DataFrame(np.append(fraud_hidden, non_fraud_hidden, axis = 0))
encoded_df[target] = np.append(np.ones(fraud_hidden.shape[0]), np.zeros(non_fraud_hidden.shape[0]))
encoded_df[target] = encoded_df[target].astype(int)
encoded_df[:3]
Now that we have encoded data we wan to train an XGBoost model to classify fraudulent accounts.
We will use first the raw data to train the classifier, then in the second part we will use the encoded data.
Before Autoencoding
train the classifier
%%time
clf = xgb.XGBClassifier(objective='binary:logistic',use_label_encoder=False,eval_metric='logloss')
clf.fit(train[features],train[target])
make predictions on the test data
test = test.copy()
test['y_pred'] = clf.predict(test[features])
Classification Report
print(metrics.classification_report(test[target],test['y_pred']))
Confusion Matrix
sns.heatmap(metrics.confusion_matrix(test[target],test['y_pred']),cmap='Blues',annot=True,fmt='d', annot_kws={'size': 16})
plt.xlabel('Predicted')
plt.ylabel('Actual');

After Autoencoding
Train test split the encoded data
encoded_train,encoded_test = train_test_split(encoded_df,test_size=0.33,random_state=42,stratify=encoded_df[target])
train the classifier
%%time
enc_clf = xgb.XGBClassifier(objective='binary:logistic',use_label_encoder=False,eval_metric='logloss')
enc_clf.fit(encoded_train.drop([target],axis=1),encoded_train[target])
make predictions on the test data
encoded_test = encoded_test.copy()
encoded_test['y_pred'] = enc_clf.predict(encoded_test.drop([target],axis=1))
Classification Report
print(metrics.classification_report(encoded_test[target],encoded_test['y_pred']))
Confusion Matrix
sns.heatmap(metrics.confusion_matrix(encoded_test[target],encoded_test['y_pred']),cmap='Blues',annot=True,fmt='d', annot_kws={'size': 16})
plt.xlabel('Predicted')
plt.ylabel('Actual');

- Here we have seen an example usage of the autoencoder architecture
- Another aspect we can observe is the contrast between the orignal data vs encoded data through the xgboost model. In the same time the loss value from the autoencoder is playing a big role in the difference between the results from the both classifiers.
- The current data in this example is not illustrating the full potention of autoencoders since it has already being processed by PCA